Introduction
We’re all busy people and it’s hard to find the time to pore through papers at conferences to stay up to date with the latest research in the field of your choice. Worry not, if you’re into Federated Learning (FL), I’ve done it for you. For this one conference. Hopefully this should save you some time so you can quickly dismiss the papers you’re not interested in and focus specifically on the ones that you are interested in while maintaining a general awareness of research in the field more broadly. I have included papers across all Oral, Spotlight and Poster presentations. You can find all ICLR papers here. And if you need an introduction to FL, take a look at my earlier blog posts here and here.
Federated Learning Papers
So without further ado, in no particular order, here are the ten papers (just happened to be a nice round number) focusing on FL at ICLR 2021:
1. Federated Learning Based on Dynamic Regularization
Durmus Alp Emre Acar, Yue Zhao, Ramon Matas, Matthew Mattina, Paul Whatmough, Venkatesh Saligrama
Institutions
Boston University, ARM
New algorithm
FedDyn
Code
None provided
Authors’ One-sentence Summary
We present, FedDyn, a novel dynamic regularization method for Federated Learning where the risk objective for each device is dynamically updated to ensure the device optima is asymptotically consistent with stationary points of the global loss.
My summary
This paper is most applicable to cross-device FL since it addresses the communication overhead of FL. Dynamic regularization modifies the regularization terms (linear and quadratic penalty terms) in each device’s local neural network at every step to make sure it is kept consistent with the global loss minimum. This means more computation can be done on device before needing to share updates and download parameters, etc. The authors demonstrate empirical results and improve on previous SOTA in this area (SCAFFOLD). Their algorithm also has the useful properties of working in both convex and non-convex settings, being fully agnostic to device heterogeneity and robust to large number of devices, partial participation and unbalanced data.
2. Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms
Maruan Al-Shedivat, Jennifer Gillenwater, Eric Xing, Afshin Rostamizadeh
Institutions
Google, CMU
New algorithm
FedPA
Code
https://github.com/alshedivat/fedpa
Authors’ One-sentence Summary
A new approach to federated learning that generalizes federated optimization, combines local MCMC-based sampling with global optimization-based posterior inference, and achieves competitive results on challenging benchmarks.
My summary
This paper reframes FL from being a global optimization problem to a posterior inference problem. But what does this actually mean? Well, if you recall your Bayesian statistics, the posterior probability is the probability of the parameters \(\theta\) given the evidence \(X\): \(P(\theta \mid X)\) i.e. the probability of something after taking into account the relevant background (priors) and evidence (likelihood). In this case, the parameters we are referring to are the actual model parameters. Local posterior inference is run on the clients to refine a global estimate of the posterior mode. The stochastic gradient Markov chain Monte Carlo method is used to approximate sampling from local posteriors on the clients. This federated local sampling stops local model weights from ever straying too far from the global optimum. Not only does FedPA result in better model convergence (faster and to better optima) than FedAvg (as shown in the figure below), it also benefits from increased local computation making it particularly attractive in the cross-device setting. Finally, the authors show that FedAvg is essentially a suboptimal special case of FedPA and report SOTA results on some benchmarks.

3. Adaptive Federated Optimization
Sashank J. Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Konečný, Sanjiv Kumar, Hugh Brendan McMahan
Institutions
New algorithm
FedOpt
Code
https://github.com/google-research/federated/tree/master/optimization
Authors’ One-sentence Summary
We propose adaptive federated optimization techniques, and highlight their improved performance over popular methods such as FedAvg.
My summary
The authors adapt the optimizers Adam, Adagrad and Yogi to work in the federated setting and show that it improves results compared to regular FedAvg algorithm with SGD on a variety of different datasets. The adaptive portion of the optimization is done on the server with the clients just running regular SGD. This ensures the method has the same communication cost as FedAvg and and thus can feasibly work in the cross-device setting. The general version of their optimization algorithm is called FedOpt and shows that the negative of the average model difference can indeed be used as a pseudo-gradient in general server optimizer updates.
4. Achieving Linear Speedup with Partial Worker Participation in Non-IID Federated Learning
Haibo Yang, Minghong Fang, Jia Liu
Institutions
Ohio State
Code
None provided
Authors’ One-sentence Summary
None provided
My summary
FL has a nice property in that it has a linear relationship between convergence and number of workers i.e. convergence performance increases linearly with respect to the number of workers. However, this has only been proven with IID datasets and/or full worker participation. The authors essentially answer what was previously an open question and show that this property still holds in non-IID settings and/or with partial worker participation.
5. Federated Semi-Supervised Learning with Inter-Client Consistency & Disjoint Learning
Wonyong Jeong, Jaehong Yoon, Eunho Yang, Sung Ju Hwang
Institutions
Korea Advanced Institute of Science and Technology (KAIST)
New algorithm
FedMatch
Code
https://github.com/wyjeong/FedMatch
Authors’ One-sentence Summary
We introduce a new practical problem of federated learning with a deficiency of supervision and study two realistic scenarios with a novel method to tackle the problems, including inter-client consistency and disjoint learning
My summary
The authors introduce a new algorithm FedMatch for semi-supervised learning. They focus on two federated paradigms, one where each client has a mix of labelled and unlabelled data and another where clients only have unlabelled data but the server has labelled data. The two core components of the algorithm are (1) an inter-client consistency loss which regularizes the models learned at multiple clients to output the same prediction and (2) and parameter decomposition such that the model has one set of weights for unsupervised learning and another set of weight for supervised learning. They show that their algorithm outperforms local semi-supervised learning and other naive baselines on a few different datasets in IID and non-IID settings.
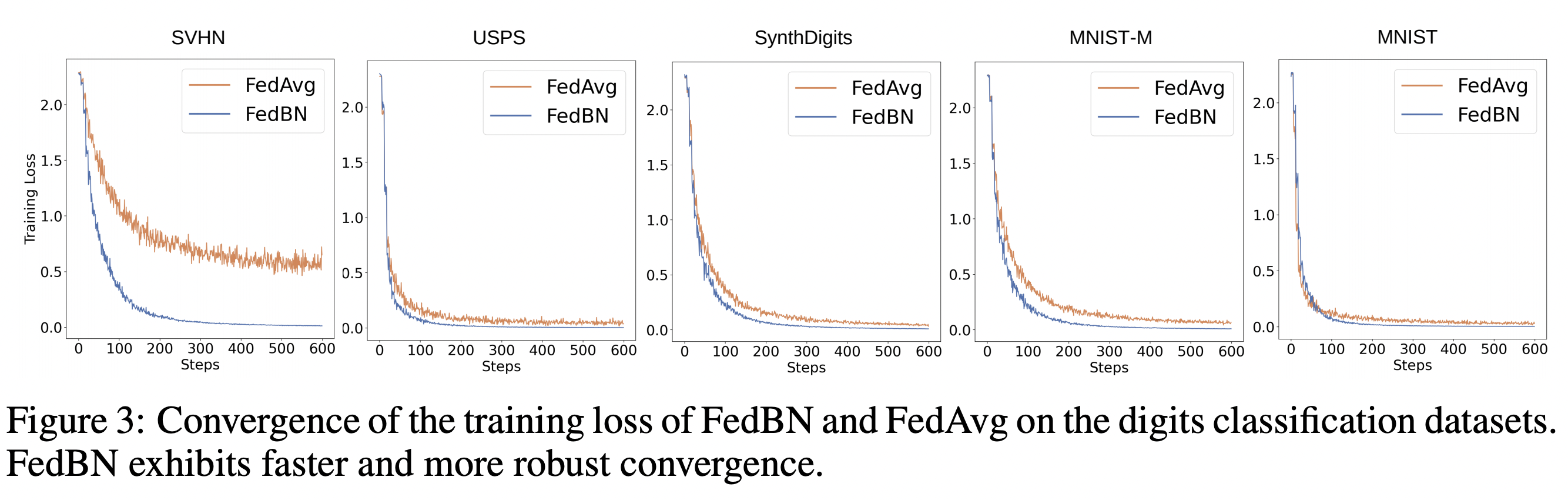
6. FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
Xiaoxiao Li, Meirui JIANG, Xiaofei Zhang, Michael Kamp, Qi Dou
Institutions
Princeton, CUHK, Iowa State, Monash
New algorithm
FedBN
Code
https://github.com/med-air/FedBN
Authors’ One-sentence Summary
We propose a novel and efficient federated learning aggregation method, denoted FedBN, that uses local batch normalization to effectively tackle the underexplored non-iid problem of heterogeneous feature distributions, or feature shift.
My summary
Batch Normalization (BN) is an important and now-ubiquitous component of neural network architectures which improves convergence and model stability. However, little work has been done to adapt BN layers to the federated setting, instead they are either usually removed or treated naively just like regular layers. This paper comes up with the remarkably simple yet effective solution of including BN layers in the model but simply not synchronizing them with the global model, so that each local model has their own personalized BN layers. This improves performance compared to standard FedAvg particularly with non-IID data where it helps to mitigate feature shifts. One caveat however is that all experiments are done with just a two layer neural network.
7. FedBE: Making Bayesian Model Ensemble Applicable to Federated Learning
Hong-You Chen, Wei-Lun Chao
Institutions
Ohio State
New algorithm
FedBE
Code
None provided
Authors’ One-sentence Summary
None provided
My summary
This paper takes a Bayesian Inference perspective to the model aggregation portion of FL. The authors’ algorithm, FedBE, can be a simple add on to the regular FedAvg (or indeed any other) algorithm. The only difference is the aggregation step which uses Bayesian Ensembling to get the best average instead of a simple arithmetic mean. Their results are most convincing when FedBE is combined with Stochastic Weight Averaging where we see significant improvements over baselines. Crucially these improvements are also demonstrated with deeper architectures like ResNets on non-IID data. One caveat however is that their algorithm relies on some computation being done by the server on a small portion of unlabelled data. This could well be an unfeasible assumption for many situations.
8. FedMix: Approximation of Mixup under Mean Augmented Federated Learning
Tehrim Yoon, Sumin Shin, Sung Ju Hwang, Eunho Yang
Institutions
KAIST
New algorithm
MAFL, FedMix
Code
None provided
Authors’ One-sentence Summary
We introduce a new federated framework, Mean Augmented Federated Learning (MAFL), and propose an efficient algorithm, Federated Mixup (FedMix), which shows good performance on difficult non-iid situations.
My summary
This paper introduces a new framework and algorithm which again addresses the non-IID data problem - this time with data augmentation. Their work builds on the MixUp algorithm which is a simple data augmentation technique using a linear interpolation between two input-label pairs \((x_i ,y_i)\) and \((x_j , y_j)\). Their general framework, Mean Augmented Federated Learning (MAFL), builds on FedAvg but with one difference - in addition to sharing model parameters, clients also share averaged (or mashed as the authors call it) data. Each client then essentially unmashes other clients’ data every round and trains with it alongside its own local data. The problem here of course is that this not very federated for an FL framework and a privacy tradeoff needs to be made. FedMix, the algorithm which builds on this framework, improves naive MAFL performance by approximating global MixUp in a more systematic way. FedMix and the naive implementation both outperform FedAvg and FedProx in non-IID scenarios on CIFAR and FEMNIST datasets. One critical missing piece in this piece of research is the privacy risk which the authors state is beyond the scope of this work.
9. HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
Enmao Diao, Jie Ding, Vahid Tarokh
Institutions
Duke, Minnesota
New algorithm
HeteroFL
Code
Authors’ One-sentence Summary
In this work, we propose a new federated learning framework named HeteroFL to train heterogeneous local models with varying computation complexities.
My summary
One of the core requirements or assumptions of FL is that all models share the same neural network architecture. HeteroFL challenges this assumption and shows that it is possible to adapt FL to scenarios where different clients have different architectures. However, this is not a complete overhaul of FL as we know it. All clients have various subsets of the weights of the global model and the goal is still to jointly train this global model. Model depth is kept the same across all models meaning that the number of neurons in each layer is what is modified. The authors demonstrate results using CNN, PreResNet18, and Transformer architectures.

10. Personalized Federated Learning with First Order Model Optimization
Michael Zhang, Karan Sapra, Sanja Fidler, Serena Yeung, Jose M. Alvarez
Institutions
Stanford, NVIDIA
New algorithm
FedFomo
Code
None provided
Authors’ One-sentence Summary
We propose a new federated learning framework that efficiently computes a personalized weighted combination of available models for each client, outperforming existing work for personalized federated learning.
My summary
Rather than modifications to FL in order to make the global model more robust, FedFomo proposes to tackle the non-IID data problem by local model personalization. There is no global model. Instead, at every step, each client receives updates from a subset of other clients based on how much that client would benefit from those parameters. This is ascertained by performance on a validation set on each client. Ideally, every client would send their model to every other client but the communication costs would likely be prohibitively large, even in a small cross-silo setting. Instead the number of models is restricted and a sampling scheme is used to sample different models depending on how much they helped on previous rounds. Their method outperforms other existing solutions.
Related Papers
While not directly FL focused, the following papers are related to the field and so I have included them below:
1. CaPC Learning: Confidential and Private Collaborative Learning
Christopher A. Choquette-Choo, Natalie Dullerud, Adam Dziedzic, Yunxiang Zhang, Somesh Jha, Nicolas Papernot, Xiao Wang
Institutions
Toronto, Vector Institute
New algorithm
CaPC
Code
https://github.com/cleverhans-lab/capc-iclr
Authors’ One-sentence Summary
A method that enables parties to improve their own local heterogeneous machine learning models in a collaborative setting where both confidentiality and privacy need to be preserved to prevent both explicit and implicit sharing of private data.
My summary
Proposed alternative to FL for improving a local model based on private data. Allows collaboration without sharing of data or model parameters and different clients can have completely different models. Instead, they will collaborate by querying each other for labels of the inputs about which they are uncertain. In the active learning paradigm, one party poses queries in the form of data samples and all the other parties together provide answers in the form of predicted labels. Each model can be exploited in both the querying phase and the answering phase, with the querying party alternating between different participants in the protocol. This work builds on PATE, private aggregation of teacher ensembles and relies on HE, MPC and DP to make the necessary privacy guarantees. The authors show the efficacy of their model with extensive experiments. However no comparison with FL is made in the experiments.
2. Differentially Private Learning Needs Better Features (or Much More Data)
Florian Tramer, Dan Boneh
Institutions
Stanford
Code
https://github.com/ftramer/Handcrafted-DP
Authors’ One-sentence Summary
Linear models with handcrafted features outperform end-to-end CNNs for differentially private learning
My summary
Addresses the problem that DP adds too much noise that makes CNN models unusable and worse than linear models. They show that handcrafting of features with ScatterNet significantly boosts performance of CNNs but they are still mostly worse than Linear models with handcrafted features. Basically, still a long way to go in this area.
Summary
So what have we learnt? Well, the focus broadly seemed to be very geared towards improving performance on non-IID data with a lot of very interesting ideas tackling different angles from BatchNorm and regularization to optimizers and model aggregation. Even where this wasn’t the focus, most papers reported results on non-IID data anyway which was great to see. Oh, we also have a whole bunch of new algorithms whose names we have to remember: FedMix, FedMatch, FedFomo, FedBE, FedBN, FedOpt, FedDyn, FedPA and HeteroFL. Do try to keep up.